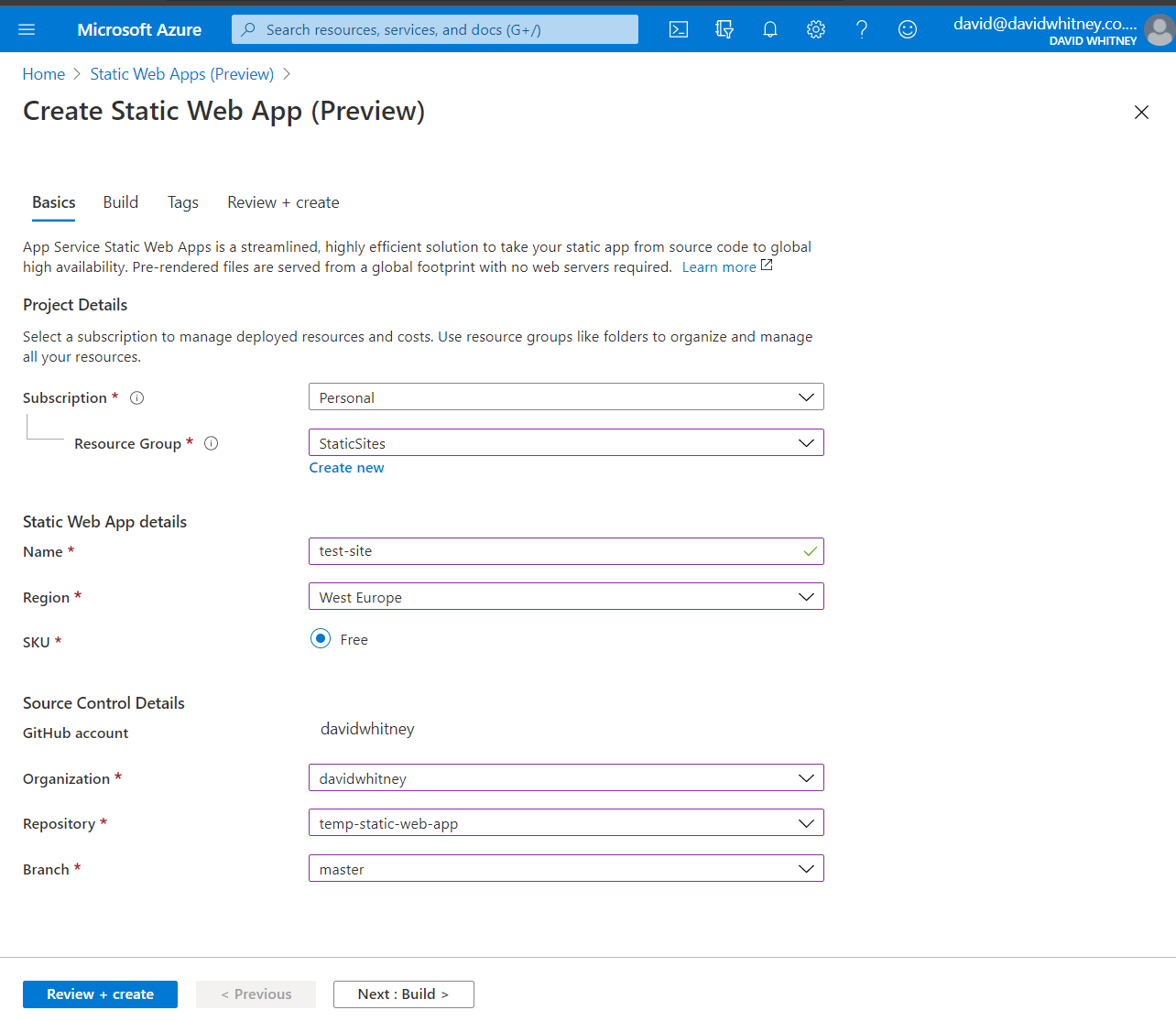
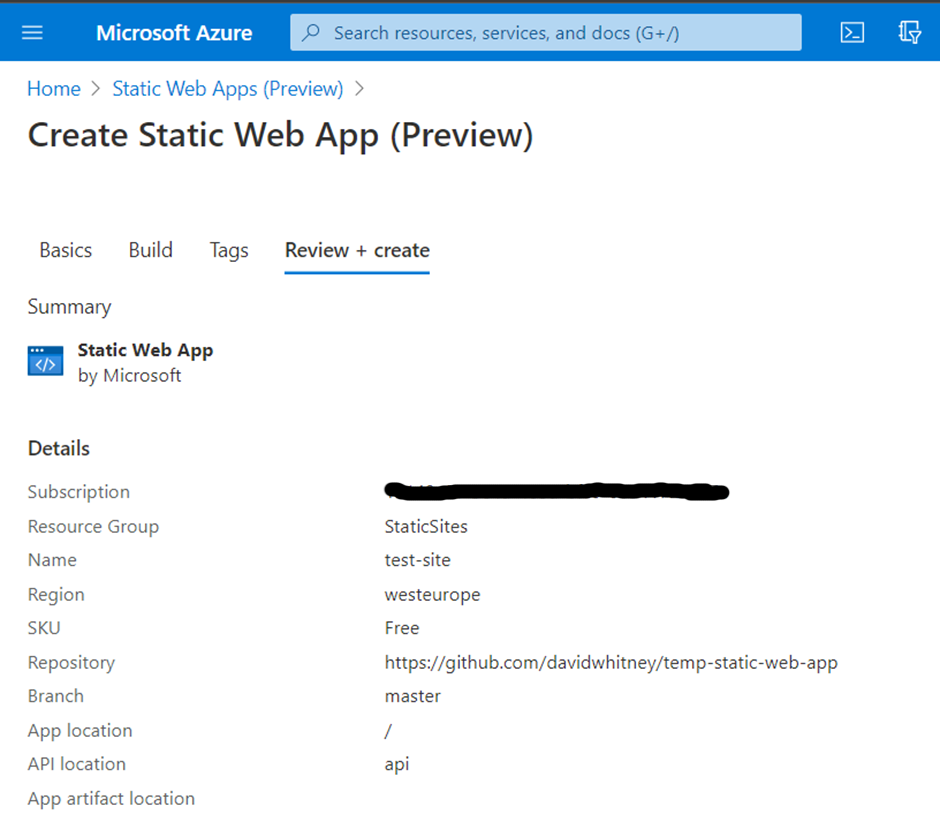
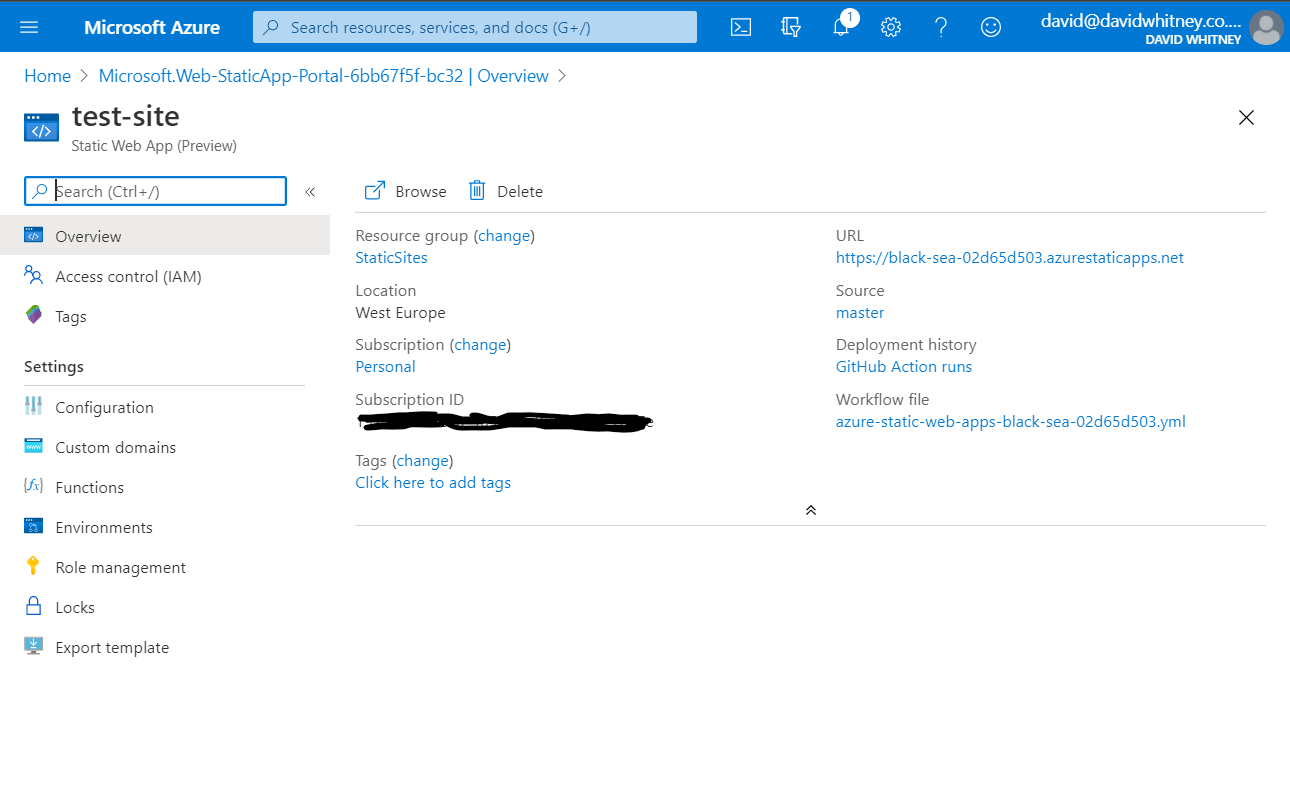
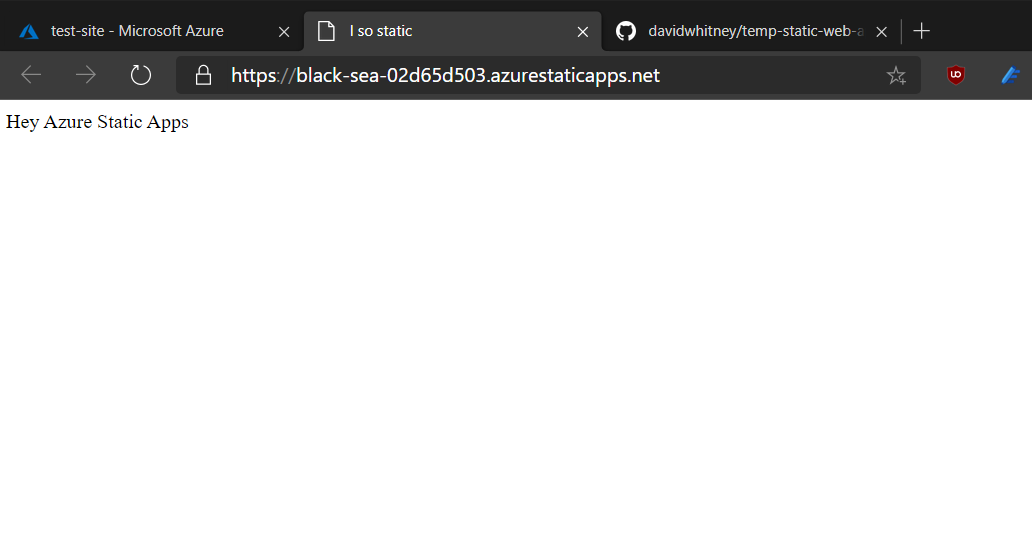
Without fail, in every consulting engagement I start, there is a common theme – that failure to articulate and scope “the software development work” pushes wide and varying dysfunction through organisations.
It’s universal. It happens to everyone. And it’s nothing to be ashamed about.
Working out what to do, how hard it is, and communicating it effectively is a huge proportion of getting work done. Entire jobs (project management, delivery management) and methodologies exist around trying to do just that.
What is slightly astonishing is how prevalent poor estimation and failed projects are in technology – especially when there’s so much talk about agile, and data driven development, and measurements.
In this piece, we’re going to talk about why we estimate, what we estimate, and how you should actually estimate, hopefully to remove some of the stress and toil from what can often seem like theatrics and process.
Why we estimate.
No more than you would hire a plumber to fix up your bathroom if they couldn’t indicate to you how long it would take or what it would cost, should you start a software project without understanding its complexity. Estimation is a necessary burden that exists when people must pay for work to get done and estimation means different things for different people.
For a team, estimation is a tool we use to understand how much work we can get done without burning out. For your C-level, estimation is a tool they use to understand what promises they feel comfortable making.
In both cases, estimation is about reducing or mitigating risk by making sure we don’t promise things we can’t deliver. At an even wider scale, estimation is simply about us understanding what we can and cannot do.
Estimation also does not exist in a vacuum - estimations are only valid for the specific set of people that make them. If you change the composition of a team or the skills it possesses, the amount and types of work that team can accomplish are going to change.
Estimation works by presuming that in fixed period, the same people should be able to do the same amount of work, of roughly similar or known types, that they have previously. It’s based around a combination of a stable team, knowledge, and experience.
Estimates are owned by the team; they are the team’s measure.
What we estimate
From the mid-2000s, User Stories have been the more-or-less-standard way of articulating work that needs to be done in software, they are meant to be an artifact that tracks a stand-alone and deployable change to a piece of software.
They should be articulated from the position of user following the mostly standard format of:
As a <type of user>
I want <some outcome>
So that <reason that this is important>
In traditional agile workflows, user stories tended to be written on index cards, with any associated acceptance criteria written on the back of the index card. When all the acceptance criteria are met, your story is complete.
Over time, the idea of tasking stories grew in popularity, and tasks were often stuck to the story cards using sticky notes. This was a useful physical constraint, as stories could only get so big before the sticky notes would literally fall off the cards.
To estimate, we estimate the complexity of each of these discrete pieces of work, in isolation. Our estimates are meant to be the measure of how much effort it would take the whole team to get the entire story into production.
It’s not uncommon to find different teams have different ideas about what “done” means for their stories – but over time almost everyone agrees that “in production” is what qualifies a story as done.
Some organisations may think they need to complete additional work in release process automation before this feels like an achievable goal, but I would always rather an estimate be honest and capture the existing complexity related to releasing software, if there is any.
Ultimately, for estimation to provide an accurate picture of your teams’ capability, any work the team performs should be captured as user stories and estimated.
Nothing ships to production without estimation.
Estimation Scales
Estimation in agile projects takes place using abstract measurements that represent the amount of effort it takes a given team to complete a user story.
Over the last twenty years, people have suggested different estimation scales for work.
These are:
- Time (usually in half days)
- T-Shirt Sizes (XS, S, M, L, XL, XXL)
- XPs “doubling numbers” (1,2,4,8,16,32…)
- The Fibonacci sequence (1, 2, 3, 5, 8, 13, 21…)
- The Modified Fibonacci sequence (1, 2, 3, 5, 8, 13, 20, 40 and 100)
- A few others not worth articulating.
The different methods offer different pros and cons.
Time is a generally poor estimation scale because it is both concrete and fixed. There is no room for manoeuvre when you estimate in time, and no negotiation. Estimating in time is the quickest way to disappoint your stakeholders the first time you are wrong.
Estimating in T-Shirt sizes is often useful for long-term projections and roadmap planning where the objective is to just get a feeling for the relative size of a piece of work.
XP (eXtreme Programming) originally suggested the doubling of numbers for its abstract estimation scale to capture the fact that work got more complex the bigger it became, and it was very easy for work to grow too big.
Later, the Fibonacci sequence was suggested as a more accurate way of capturing that same concept, but instead as an exponentially increasing curve, to capture the escalation of complexity. This sequence was later modified and capped off with 20, 40 and 100, for practical reasons (nobody wants to endlessly debate which enormous number is the right one to pick).
Most teams that do estimation end up using the Modified Fibonacci sequence because it captures the increasing complexity of unknown, unknowns, along with being simple to remember, and explicitly not being a measure of time.
How to estimate
In a planning meeting, the entire team that will be working on the work get together and read through the stories that have been written for them. These stories are usually prioritised by a product manager or product owner, but estimation doesn’t require this to be useful.
As a team, short 2–3-minute discussion about each story take place, sharing with each other any context or information. During this discussion, people can note down the kind of tasks that completing the work would require, discuss special knowledge they have about the story, or provide any additional context.
As a rule of thumb, it’s a good idea to list the kinds of activities involved - “some front-end work, maybe a new API, some configuration, some new deployment scripts, some UI design” as a way of highlighting hidden complexity.
This is because the more moving parts there are to a story, the more complex it will become.
At the end of this brief discussion and crucially at the same time using either planning poker cards or just by holding the pre-requisite number of fingers up as if playing a game of stone paper scissors, the team should all estimate the complexity of a story.
The team estimates simultaneously to prevent the cognitive bias of anchoring, where whoever gets in first with a number will “set the tone” for future estimates, consciously or not.
The estimate is then noted on the story card, and everyone moves on.
It’s exceptionally important that the entire team estimates every card, and the estimates are for the whole amount of effort required of the entire team.
One of the more common mistakes in estimation involves people estimating only the work for their specific function (Front-end and back-end estimates, dev and QA estimates, design and dev estimates, are all equal anti-patterns). This is problematic, because it hinders a shared understanding of complexity by all team members, along with occasionally driving people towards the anti-pattern of maintaining estimates for individual team functions.
The team estimates as a whole to increase its coherence, to share it’s understanding of the complexity of its work, and most importantly to replace the mental model of a single contributor with that of the whole team.
There are a few common points of conflict that happen during estimation sessions that are worth calling out.
The team can disagree on the score they are settling on.
This will happen frequently – imagine you’re estimating using modified Fibonacci and half the team believes the story to be worth 5 points, while the other half believes the story to be an 8-point story. You can resolve this conflict by always taking the higher estimate.
There is often resistance to this approach from product owners responsible for trying to maximise for team throughput but the truth to this is very simple – it’s always easier to under-promise and over-deliver than to do the opposite and disappoint people.
If a team over-estimates some work, they’ll have plenty of capacity to schedule in subsequent work anyway. If the larger estimate was true, and the smaller number was chosen, it jeopardises work that may have been promised outside of the team.
The range of story points expressed by the team in planning poker is too wide.
Another common scenario is where vastly different numbers are selected by team members. Perhaps there’s an outlier where one team member thinks a piece of work is a 1-point story against an average of 5 points from everyone else.
You can resolve this conflict with a short discussion – perhaps that team member knows something that wasn’t shared in the prior discussion. Estimates can be discussed and revised at this stage by negotiation.
The team argues a story is inestimable, or just too big.
If the team feels the story is not refined enough to be estimated as actionable work, they may push back on the grounds that the story is too big for estimation.
When this occurs, the team should either, collectively, during planning, decompose the story into smaller stories that can be estimated or, defer the story to do the same in another meeting.
If stories are frequently inestimable, unclear, or lacking sufficient detail, schedule a refinement session to occur every other day for 45 minutes. In this session, the team can collectively refine and write stories, until the backlog of work to be done becomes more approachable. The team should choose to what extent these sessions are required based on their comfort levels with the work present in the backlog.
For particularly sticky stories that appear to get repeatedly rebuffed for being inapproachable, it might be advisable to write up a spike. A spike is a time-boxed story that results in further information and research as its output and should inform the refinement and rework of stories deemed too complicated or unapproachable.
If you find yourself writing spikes, be sure to articulate and write acceptance criteria on the spike that state the exact expected outcome of the work.
Planning and estimating work often starts from a place mired in detail and complexity, but with the use of frequent refinement sessions and lightweight estimation conversations, it should mature to be more predictable and simpler as your team gains an increasing coherence.
Estimation and planning with newly formed teams will often take a few iterations to level out, as the team members slowly gain a greater understanding of the kinds of work that happens in the team.
Understanding velocity
Velocity is the term used to describe the rolling average of story points completed during iterations.
A teams velocity is an average, and represents the work of the team in it’s current configuration. If your team makeup changes (the number of people, the distribution of skills, holidays) your velocity will change accordingly.
Velocities are used during planning exercises to understand how much work a team can realistically expect to get done in an average iteration. It’s important to understand that velocity is not a target to be exceeded – it’s an abstract number that represents the sustainable pace of the team.
Velocity is for the team and is a non-comparable measure.
Two teams, even two teams in the same organisation, reporting the same velocity number will always be talking about different things. While it is often tempting to try and baseline or compare teams based on velocity metrics, you are not comparing like for like and any statistics gleamed from them will be false.
Velocity is designed to be used in the following scenarios:
- Understanding how much work the team can do in each iteration.
- Planning for holidays and sickness by deliberately reducing velocity
- Understanding the predictability of a team – inconsistent velocity is a key indicator of poor story writing hygiene or an unpredictable environment.
The goal of a team is to have a stable velocity because a stable velocity means a team can make promises about when stories will be delivered.
Estimating roadmaps, and projection
Estimation is often desired during long term planning exercises such as company roadmaps, quarterly reviews, or other long term vision activities.
It’s useful to understand that estimation is like a shotgun – it is very accurate at short-range and decreases in accuracy the further away your plan or your schedule is. Consequently, detailed estimates become useless at range.
This frequently leads to tension between business leaders that want to communicate to their investors, the public, or their other departments and technologists, who embrace the uncertainty of high-level planning exercises.
Road mapping and other high level estimation processes are an entirely valid way for a business to state it’s intent and its desires but what they are not, and cannot be, are schedules.
We can use high level estimating to help these processes with a few caveats. Firstly, we should always use a different estimation scale for high level estimates. This is important to ensure that wires do not get crossed and estimations conflated.
Secondly**,** high-level estimation processes should and will lack implementation detail, and as a result will end up with items often categorised broadly as either easy, average, large, or extra-large.
This idea of vague complexity is important for a business to understand the order of magnitude size of a piece of work, rather than day-and-date estimation of expected delivery. Once this rough size is established, further work will be required to produce more useful, team centric estimates.
An alternative approach to detailed roadmap projections, and I promise I am not joking, is counting.
Usually, roadmaps are vast and contain many themes and pieces of work, and it’s often enough to simple count the number of items and ask the honest question “if your entire company was working on this roadmap, could you do one thing a day”. If the answer is no, repeat the question for two days, and three days until you work out what you think your “multiplication factor” is.
Often, this number is accurate enough to understand how long a roadmap might take, in conjunction with some simple “small / medium / large” estimates over the roadmap items.
Estimation and dates
If estimates were dates, they’d be called dates, not estimates.
Estimates exist to help teams understand their sustainable pace and velocity. Using estimates to reverse engineer dates is a dangerous (if sometimes possible) non-science.
Rather than attempting to convert story points back to days-and-dates, teams should focus on providing stable velocity and release windows.
A team with a stable velocity should be able to predict the earliest point at which a feature should be delivered by combining their estimates, their capacity, and the expected end of the iteration that work is prioritised into.
The earliest point work could be expected, should be that date.
#NoEstimates
“But I read on twitter that estimates never work! All the cool kids are talking about #NoEstimates!”
Over time, healthy and stable teams refine their stories down to consistently shaped manageable chunks. As these teams cut through their work, they often find that their estimates for stories are always the same leading to a scenario where “everything is a 5!” or “everything is a 3!”.
This is amazing for predictability, because what those consistent numbers really represent are a shared mental model and a known sustainable pace.
Now, because estimates are deliberately abstract and deliberately the teams own internal measure if everything is a 5, and all stories are always the same size, and they’re always a 5. Then, well, everything could just as easily be a 1.
When everything is the same size, then the goal of estimation has been reached.
As a result, you may hear people from highly functioning, long term and consistent teams advocating for no estimates because they are at the far end of this journey and have probably developed internal mechanisms for accounting for team capacity changes.
In contrast to this, teams that do not share a mental model, and a coherent internalised idea of average story size absolutely require estimation to help them walk to that place of predictability and safety.
It’s unrealistic to expect teams to magically develop a shared idea of story size and capability without giving them tools – like estimation – to measure their progress on the way.
When your team reaches a comfortable place of coherence, you’ll know when you can drop estimates.
FAQs
I feel like I’ve been talking about estimation and planning for a decade and a half in various forms, and people have plenty of questions about the topic. Here are some of the most common ones.
Should we estimate tasks and subtasks?
You estimate anything at all that the team must work on, to do some work.
There’s certainly an anti-pattern supported by digital tools with a lack of physical constraints (you can’t stick loads of subtasks onto an index card!) that leads to explosions of subtasks.
Often this is people using subtasks as a specification, rather than doing the work to split up and refine a story that is too large to reason about.
I would always prefer any tasks be present as notes on a story card, rather than things that can move, be reallocated, and block on their own. They’re either an integral part of the story, or they are not.
Either way, yes, you must point them if they are work.
How do we estimate technical tasks?
This comes up a lot – and there are two answers.
Either:
- The technical task as part of the work of a user facing story, and its “estimate” is just part of that work.
- You articulate a technical user persona, who has desires of the system, and the “technical task” is a user story that meets a need for that user.
In both cases, you estimate the story like any other, based on the complexity for the whole team to complete that change in production.
Should we estimate bugs?
Bugs are only bugs when they’re on production – before that point, they’re just unfinished work.
The effort it takes to fix any bugs you find during development is part of the estimation of the story and observations made by testers while you’re building is just part of the work.
Once a bug has made it to production? Well, it’s just another story to fix it, and it should be estimated, like any other story and these stories will count towards your velocity, like any other work.
Should we estimate front-end and back-end tasks separately?
No. Estimates account for the work of the entire team, communication overhead, and delivery. Any work that people do should be accounted for in the teams estimate.
Why are spikes time-boxed and not pointed?
Good catch! Spikes are the anomaly in this process because they are timeboxed.
They are timeboxed because they do not result in work shipped to production but result in more information. They should be treated as if whoever is doing the work is removed from the iteration for the duration of the spike, and the amount of work done in your iteration should be reduced accordingly.
Over-reliance on spikes is an anti-pattern – they’re here to help you break down meaty pieces of work, not to push analysis downwards into the team.
If we don’t finish a story at the end of a sprint, should we re-estimate it at the start of the next one?
It doesn’t really matter a huge amount, you either leave the story on your board, and reduce incoming work until everything is finished, or you re-estimate your story for “work remaining”.
I don’t like re-estimating stories once they’re being worked on and seeing as it’s less work to just do nothing, I’d recommend doing nothing and allowing the fact that velocity is a rolling average to deal with any discrepancy in your reporting.
You need different tools at different times.
Estimation and planning are probably some of the more frequently debated agile methods.
The good news is that you get better at estimation and planning by practicing it, and by refining your stories, and by functioning increasingly as a team rather than a group of individuals.
As you work towards a level of coherence where estimates become less useful, it’s important to remember that at different levels of maturity, teams need different things, and that’s totally, totally fine.
The purpose of estimation is to help give you a sense of predictability. Do not be afraid to change the process if it’s not helping you achieve that goal.
While we cannot predict the future, we can get better at estimating it with practice.